Term 1 Project 3 Udacity Self Driving Car Nanodegree
Project 3 in Term 1 is amazing! We teach the computer to drive a car in a virtual environment! We use Keras Machine Learning Library to build a program that can take in videos of us driving in the virtual world and from the videos learn to drive!
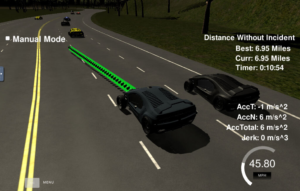
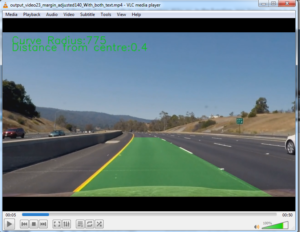
These pictures show you how it works. Udacity provide a special virtual environment for you to use. It does look like a computer game but there is more than that going in. There are 2 modes one for you to drive and one for the computer to drive. When you are driving you can select record and images from the car will be recorded along with the steering angle that you were using at that moment. That’s it ! No other information is recorded from just a series of pictures and steering angles. From just that the program has to figure out how to drive. It looks at the images to decipher some kind of pattern and associates that with a steering angle. In this way it learns or clones your behavior.
Each lap of the track should only take a couple of minutes but during that time we may collect as many as 10,000 images! This creates a lot of work for or computer and using a GPU in your computer or the cloud can really help. Another thing we can do is crop the image to reduce the amount of memory required. We can save half the memory if we reduce the image size by half.
There is another very important reason why we crop. Sometimes we might turn left and there happens to be a tree on the side of the road. We don’t want the computer to learn to turn left every time it sees a tree we want it to turn left when the road goes left.
By cropping the image so that trees are not visible we are reducing the chances the computer will learn the wrong patterns. In this way cropping the images improve both processing time and the quality of computer learning.
On the left we have some examples of images before and after cropping. These are the images recorded by the computer and show the simulated view looking forward from inside the car.
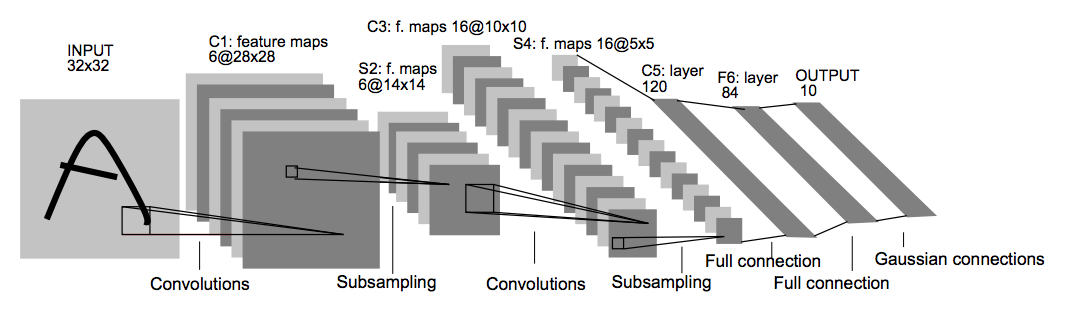
LeNet
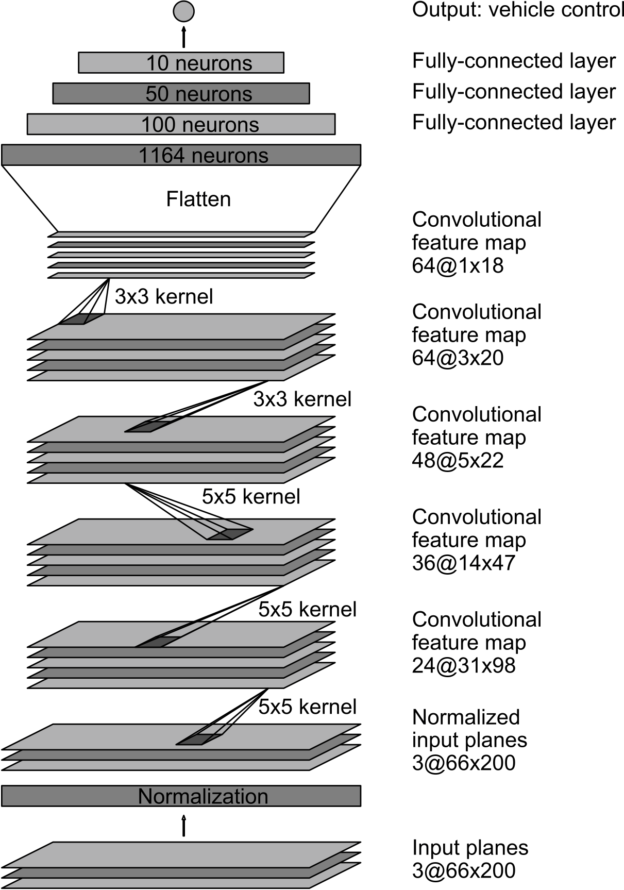
NVIDIA
The data from the track was fed into our computer learning models. We were free to make up what ever we liked and it was good to play around with different ideas. Usually it was best to try well established models as a starting point and then add or subtract from that point. 2 Heavy weight contenders for best model ever are the LeNet model described in Project 2 and the model on the left as developed by NVIDIA corporation The NVIDIA model was specifically design for self driving cars and it was interesting to see how much better it might be compared to LeNet which is now relatively old and was designed to do something quite different, recognise handwriting.
It quickly became apparent that the quality of data imputed made a huge difference. This really follows the classic computer axiom for Garbage in Garbage out . If you had recordings of a car mostly turning left the computer model would tend to turn left too much. If you drove right on the kerb the computer would do the same. So imputing quality data was important. A few tricks were used to boost the amount of data. The car had 3 camera positions recording left, center and right, I used all 3. Also we could mirror each image individually and this countered the left turning bias in the data perfectly. This required some image processing to duplicate and mirror flip each image left to right individually and was part of the preprocessing of the data before it was fed into the model. I also used more than one lap and there was also a second track to try out.
I experimented with up to 6 tracks of data but found 3 laps of driving in the center using 3 camera angles and mirroring to give good enough to pass results. Going higher than that took too long and didn’t improve results enough to justify doing.
I almost got the LeNet good enough. I could get it to go around OK but it touched the kerbs a couple of of times. NVDIA was a just that little bit better consistently and was the model I used in the final version. As suggested by the rubric I added drop out to the NVIDIA model in 2 places to modify the model.
When the whole thing was working pretty well I tested it on the dreaded track 2 which was very different and much more complicated than track 1. There is an option to temporarily take over the controls and the best I could do was to help the car on a couple of occasions. There were a few things dramatically different to what the computer had previously seen such as a very tight hairpin corner and the car always seemed to turn just a little too late and get stuck at the hairpin bend .
Training the car on track 2 and then running it on track 1 gave some important insights into behavior cloning and how a human can think you are teaching the car one thing but actually the computer is learning something else.
For example I recorded a few laps right in the center of track 2 carefully following the center line. This attempt was terrible on track 1. It took me a while to understand the track 2 had a center line track 1 does not. So when I recorded driving in the center of track 2, I was also teaching the computer to drive on top of a white line . The closest thing to a white line on track 1 was the kerb of the road so it drove consistently on top of the kerb .
Another attempt on recording track 2 was similarly interesting. I recorded staying in one lane I drove on the right hand side between the center line and the kerb. I was so confident this would work well on track 1 . What happened was the car drove way over to the right and between the edge of the kerb and the white line or edge of the road. This perplexed me until I realised that I had trained the car to drive between two lines on the right side and on track 1 the two lines at the edge of the road the are similar are the kerb and edge of road. So the computer was trying to drive between the only 2 lines it could see and it drove the whole way around until the bridge in the same relative position. This was a great learning for me. It is easy to think you are training a model to do something but the computer may be picking up on something you had not anticipated.